
Cloudera Iceberg REST Catalog 如何助力企业实现开放且 AI 就绪的运营
互操作性长期以来一直是一个流行词,而不是企业在实践中可以依赖的能力。相反,数据架构师常常被迫拼接碎片化的系统,首席数据官面临孤岛治理带来的巨大风险和供应商锁定,平台领导者也受限于为团队提供一致的数据视图。无论是由合并、多云战略,还是外部合作伙伴关系驱动,模式都在重复:成本上升、创新速度变慢,以及有限的能力以信心扩展人工智能。
在 Cloudera,我们帮助客户应对这些挑战——断开的元数据层、重复的数据管道以及无法跨工具扩展的治理模型——始终致力于实现开放的、AI 就绪的企业,实现大规模互作性。
为什么开放对企业级 AI 如此重要
要扩展人工智能工作负载,组织需要对推动它们的数据具有可见性和控制力。元数据智能在这个方程中起到至关重要的作用,使组织能够了解数据存储的位置、结构方式以及在团队和工具之间的使用情况。
通过 Apache Iceberg 和 Iceberg REST Catalog 等开放标准,企业获得了一个统一的元数据层,支持零 ETL 数据共享,实施治理,并在分析和 AI 引擎之间实现安全的互操作性。这个基础将碎片化的基础设施转变为一个互联的、AI 就绪的数据架构——在这个架构中,元数据成为加速访问洞察的关键,同时还能保持信任。
开放、安全、简单:Cloudera Iceberg REST Catalog
Cloudera Iceberg REST Catalog 为我们的开放数据湖仓提供支持,帮助组织简化架构、减少重复并将安全数据访问扩展到任何需要的地方。
它作为一个通用、互作的元数据层,提供跨工具、云和团队的 Iceberg 表零复制访问,使开源和第三方工具能够访问相同的数据。特点和优势包括:
- 开放且引擎无关:提供基于标准的 API,支持 Athena、Databricks、Redshift 和 Snowflake 等工具——实现互操作性,避免厂商锁定
- 设计解耦:将查询引擎从后端元存储中抽象出来,降低复杂性并提升跨环境的可移植性
- 实时元数据访问:支持从兼容 Iceberg 的元存储库进行快速、最新的元数据查询,提升团队间的数据可见性
- 受控且安全:将细粒度的访问控制、行级权限和企业身份访问管理(IAM)集成(例如 LDAP 和 OAuth2)扩展到所有连接的系统,从而确保大规模下策略执行的一致性
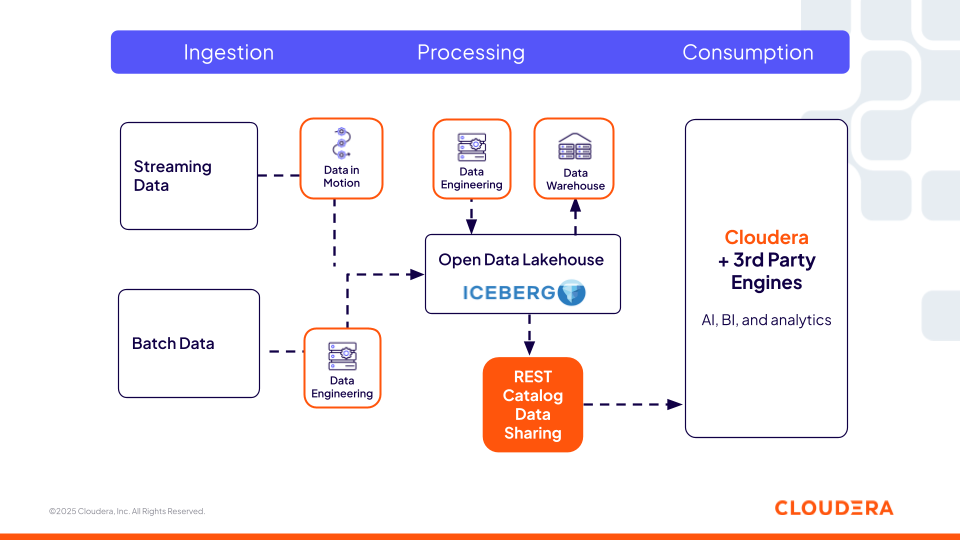
图 1.Cloudera 的 Iceberg REST Catalog 提供了一个通用且可互作的元数据层,使开源和第三方工具能够访问相同的数据。
真实世界的使用案例和 Iceberg REST Catalog 的影响
以下真实案例展示了组织如何利用 Iceberg REST Catalog 简化数据堆栈、降低总拥有成本(TCO)并加速价值实现时间——同时将数据保存在应有的位置。
这些例子共同展示了 Cloudera 开放且互作性的方法如何加速 AI 成果,推动企业规模的运营效率,并实现安全性与合规性。
数据共享:将 AI 应用扩展到 3,000 多个跨平台用户
一家豪华汽车制造商在使用 Databricks 与外部合作伙伴安全共享数据方面面临日益严峻的挑战。传统方法依赖数据复制,这带来了成本、复杂性,导致架构不灵活。
通过采用 Iceberg REST Catalog,客户实现了跨内部系统和外部平台的安全、零 ETL 数据共享。这种开放的、基于标准的方法使他们能够选择最适合这项工作的工具——使用 Spark 处理复杂的数据管道,使用 Impala 进行快速 SQL 分析。凭借这一基础,公司将 AI 应用程序扩展到 3,000 多个用户,同时保持对数据访问的完全治理和控制。
数据仓库优化:降低数据传输成本 74%
在一次合并活动之后,一家全球卫星公司在统一锁定于专有系统中的分散数据时遇到了重大障碍。由于缺乏一致且可互操作的数据层,他们的人工智能和分析项目扩展缓慢且难以管理。
Cloudera 的开放数据湖屋架构由 Iceberg REST Catalog 支持,帮助客户整合这些孤岛,并为所有 AI 和分析工作负载建立单一的真实来源。通过直接在 S3 中查询托管的 Iceberg 表,他们消除了冗余数据管道和重构工作的需求,导致数据移动成本降低了 74%。
演示:深入了解通过 Cloudera 的 Iceberg REST 目录进行数据共享
该交互式演示通过金融服务场景将 Iceberg REST Catalog 变为现实。在虚构的 Parent Bank,不同的团队使用他们喜欢的工具——如 Snowflake 和 AWS Athena——来安全地访问一个受控的数据源,而无需复杂的 ETL 或昂贵的数据移动。
如需深入了解该产品及其如何为您的组织带来益处,请浏览这些资源:


