Cloudera Data Warehouse
在不影响速度、成本或安全的前提下,管理和分析成千上万的并发用户的海量数据。

概述
随时随地轻松地将所有数据转换为有意义的业务洞察力。
一种云原生、自助式分析体验,在所有规模和类型的数据上都优于其他数据仓库,同时实现经济高效的扩展。
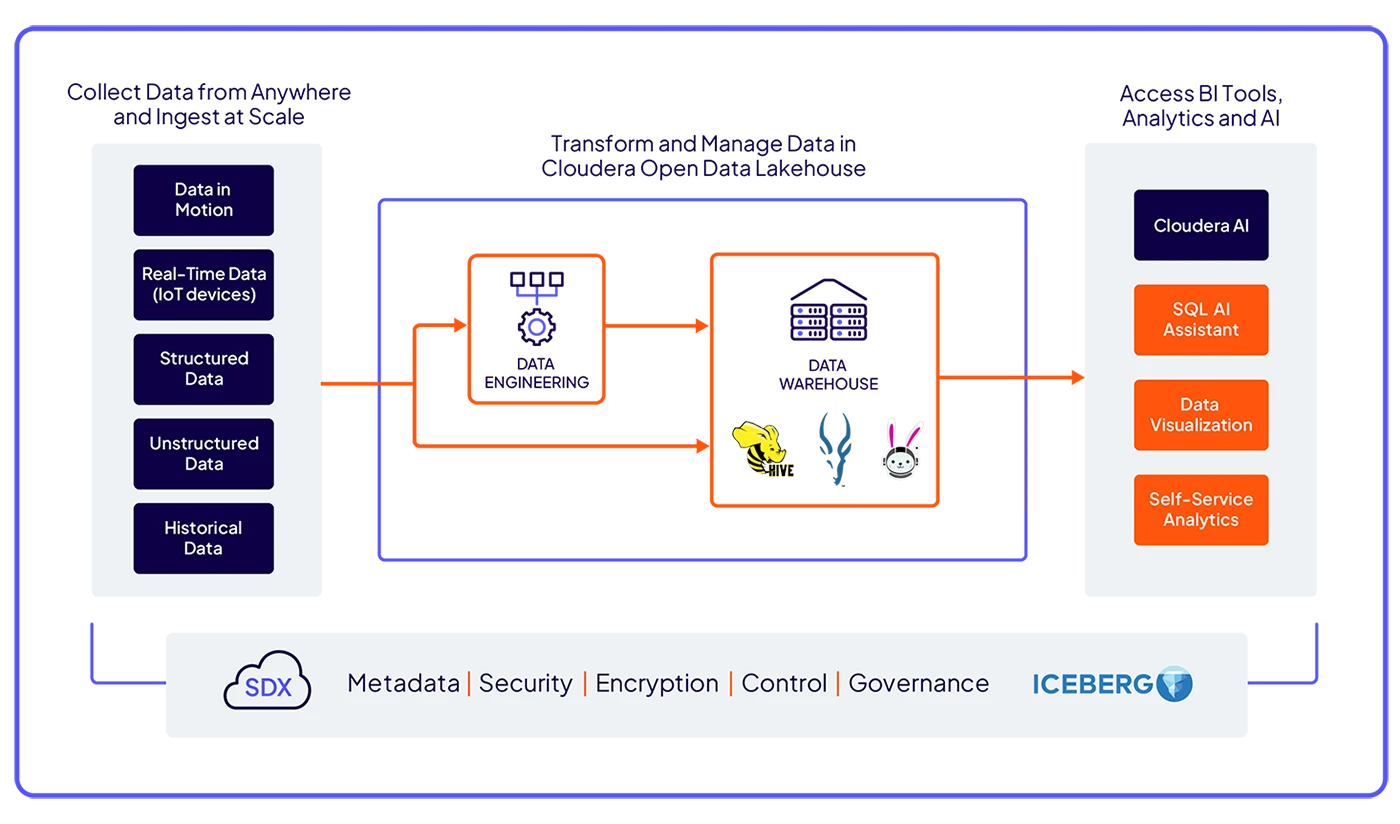
解锁强大的洞察力,借助高级 SQL 引擎实现高速查询、智能自动化、AI 辅助 SQL,以及优化的工作负载性能。
在由 Apache Iceberg 支持的统一平台上,自信且安全地构建分析工作流,确保数据随时随地无缝访问。
通过云原生、开源引擎提供工作负载灵活性,同时对您的数据保持完全控制,并避免供应商锁定。
使用案例
使用适合的引擎来处理相应的工作负载,以降低成本。
-
利用联合查询和即席探索获得更深入的洞察
使用单个 SQL 查询分析来自各种系统的数据。
-
增强决策支持和商业只能
可随时随地自助访问任何数据,快速提供重要见解。
-
通过 ETL 管道和批量处理提升数据质量
访问结构化和非结构化数据的灵活快速分析。
-
多功能分析与 Apache Iceberg
转换和准备大量结构化数据,用于下游分析和报告。
-
利用联合查询和即席探索获得更深入的洞察
使用单个 SQL 查询分析来自各种系统的数据。
-
增强决策支持和商业只能
可随时随地自助访问任何数据,快速提供重要见解。
-
通过 ETL 管道和批量处理提升数据质量
访问结构化和非结构化数据的灵活快速分析。
-
多功能分析与 Apache Iceberg
转换和准备大量结构化数据,用于下游分析和报告。
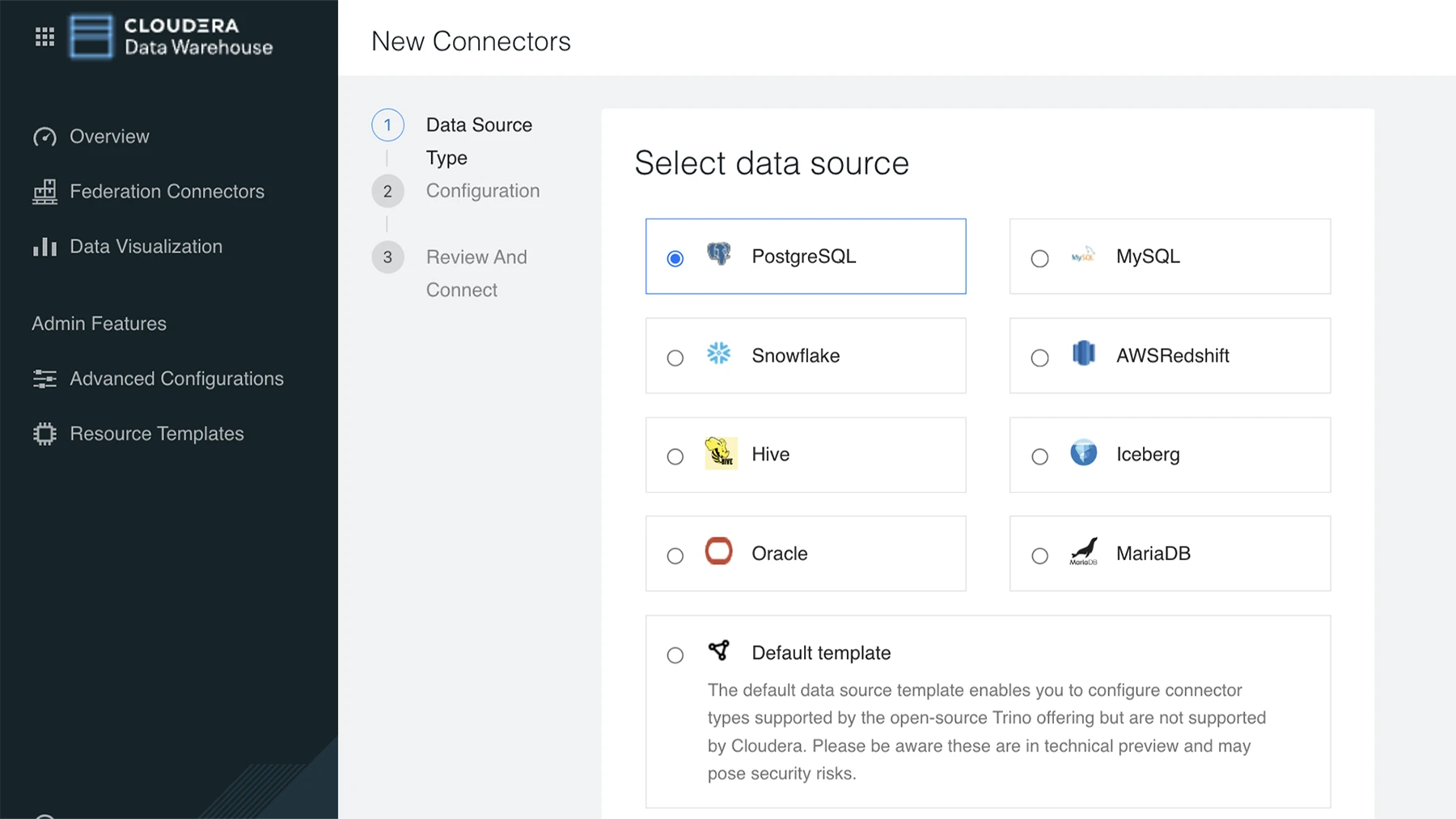
赋予数据分析师和科学家查询来自不同来源的大量分析数据集的能力。
分析来自不同来源的数据,无需进行数据迁移或复杂的集成。

通过自助服务和低延迟访问事件和时间序列数据,增强用户能力。
构建交互式报告和仪表板,大规模使用实时数据并快速执行查询。
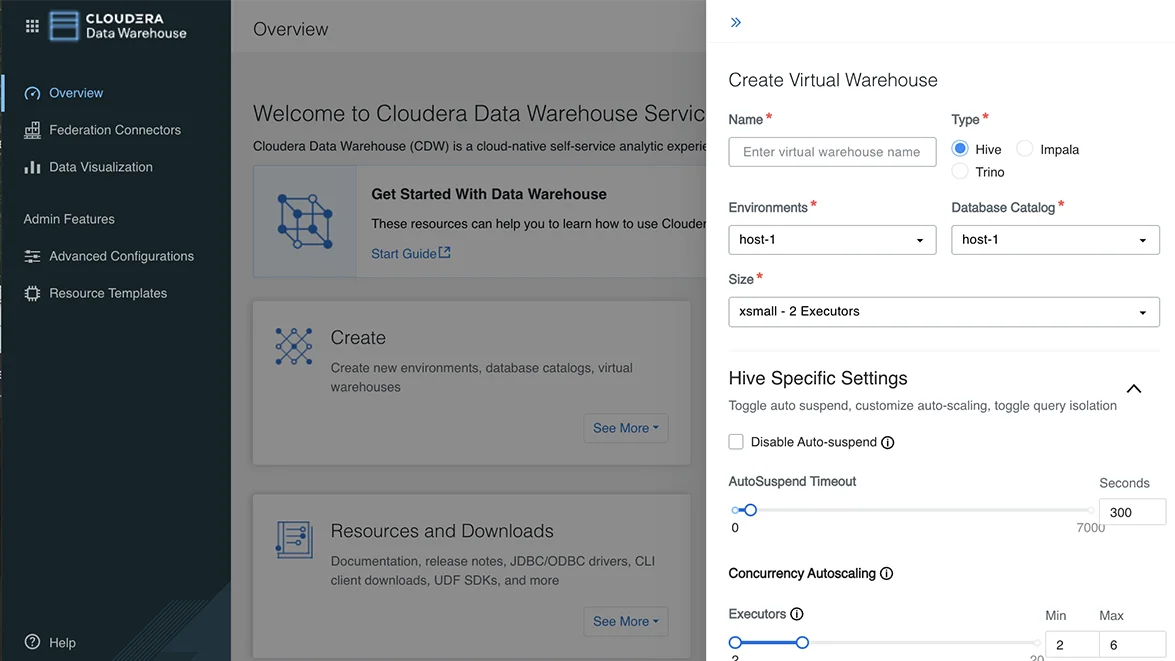
对海量数据集和高频计划任务执行复杂查询。
支持大量结构化数据的转换和准备工作,以便进行下游分析和报告。

让用户能够利用自己喜欢的工具进行数据分析。
实现与第三方引擎的无缝互操作性,统一组织内的数据,促进协作增强。




{kind=link}