湖仓创新
通过 Cloudera Lakehouse 服务,在适当的时机为您的企业、代理和私有 AI 提供合适的上下文。

概述
提供快速、安全且优化的人工智能就绪数据。
Cloudera Lakehouse 服务连接跨平台、云和数据中心的数据源,使数据易于访问并为下游 AI 工作流程和应用程序做好准备。
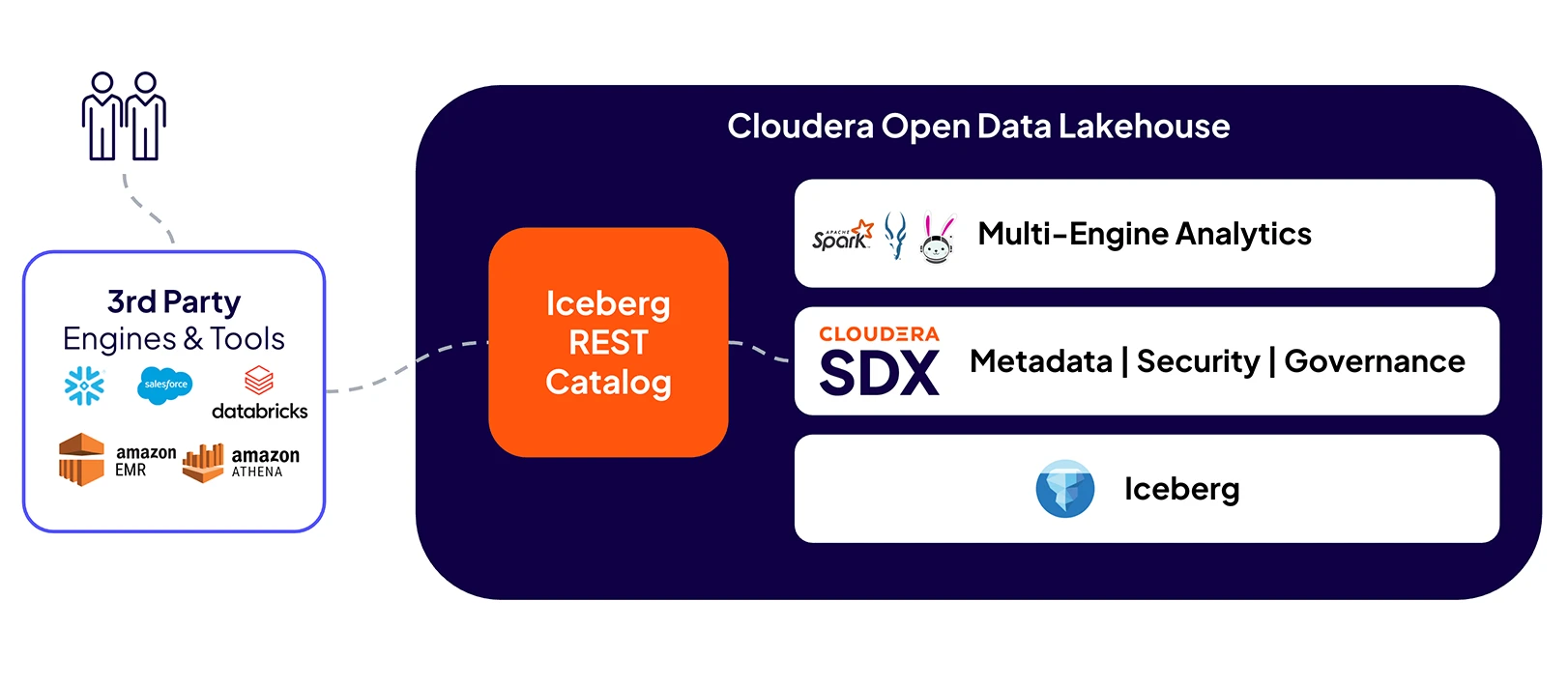
提升数据互操作性,使不同团队能够安全且轻松地协作处理同一数据。
构建一个基于开放标准的灵活数据平台,设计和优化以运行任何工作负载。
提供跨环境的无缝数据和工作负载可移植性,采用混合湖库架构。
使用案例
实现安全、治理且具成本效益的数据共享,并扩大人工智能规模。

提升数据可访问性,并在所有数据源中实施统一的安全与治理。
使业务团队能够通过他们选择的 Iceberg REST 兼容引擎查找和访问数据。

实时向人工智能代理提供可信、高质量、完整且干净的数据、元数据和语义。
连接源,打破壁垒,使所有数据快速可访问,便于 AI 智能体和工作流轻松使用。
提供无需任何 ETL、数据复制和数据移动的数据共享。提高协作效率,使团队可以使用首选的工具。促进数据再利用和自助访问。
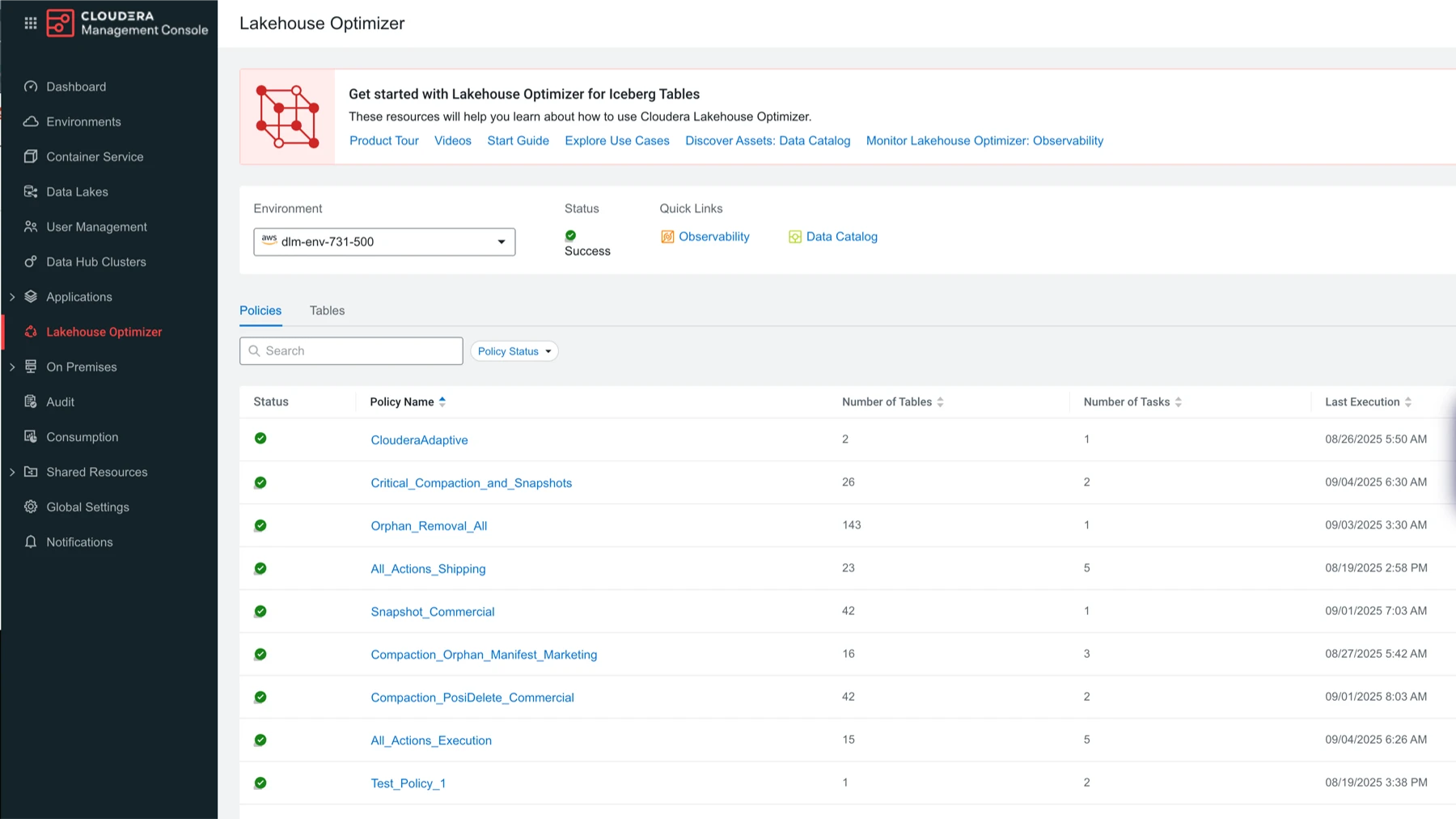
提供预测性、智能化、与引擎和存储无关的优化。Apache Iceberg 表维护自动化消除了人工数据管理任务,确保开放数据湖仓保持高性能、可扩展和高成本效益。
提供强大的业务连续性以及灾难恢复和备份功能,使企业能够在私有云或公共云中的不同 Cloudera 集群上复制表级数据和元数据。



进入下一步
深入了解 Cloudera 开放数据湖仓和湖仓服务如何支持您的企业级、代理型及私有 AI 项目。
Open Data Lakehouse 免费培训
通过 Cloudera Education 提供的免费培训,了解 Apache Iceberg 的基础知识。
开放式数据湖仓文档
了解如何启动并运行 Cloudera Open Data Lakehouse。