Cloudera Streaming
利用 Apache Kafka 和 Apache Flink 的强大功能创建高性能、实时的服务和应用程序。

概述
您构建实时应用的基础。
Cloudera Streaming 专为关键任务型应用而设计。它使用 Apache Kafka 和 Apache Flink 进行实时数据处理,每秒处理数百万个事件,延迟低,一致性有保障。
通过使团队能够轻松构建实时 ML 模型和高级预测分析的可靠管道,加速应用程序开发。
在本地或云环境中,以一致、安全且可控的方式开发、测试和部署流媒体应用程序。
构建更快、更安全的数据管理和分析应用,具备最佳性能和可扩展性,无论何处。
使用案例
启用支持您业务运作的应用程序。
-
实时欺诈检测
构建能够实时分析交易流的微服务。
-
动态客户体验
构建事件驱动型应用程序,使其能够在交互数据创建后立即响应。
-
预测性维护和优化工业流程
构建能够从连接设备中获取和分析大量数据的应用程序。
-
企业级安全性
通过与 Cloudera 平台集成,确保数据生命周期的安全和管理。
-
实时欺诈检测
构建能够实时分析交易流的微服务。
-
动态客户体验
构建事件驱动型应用程序,使其能够在交互数据创建后立即响应。
-
预测性维护和优化工业流程
构建能够从连接设备中获取和分析大量数据的应用程序。
-
企业级安全性
通过与 Cloudera 平台集成,确保数据生命周期的安全和管理。

利用 Kafka 的保证交付和 Flink 的有状态处理技术,建模并应对复杂且不断演变的欺诈威胁。
开发需要状态、上下文和复杂事件处理以实现实时模型评分的复杂应用程序。
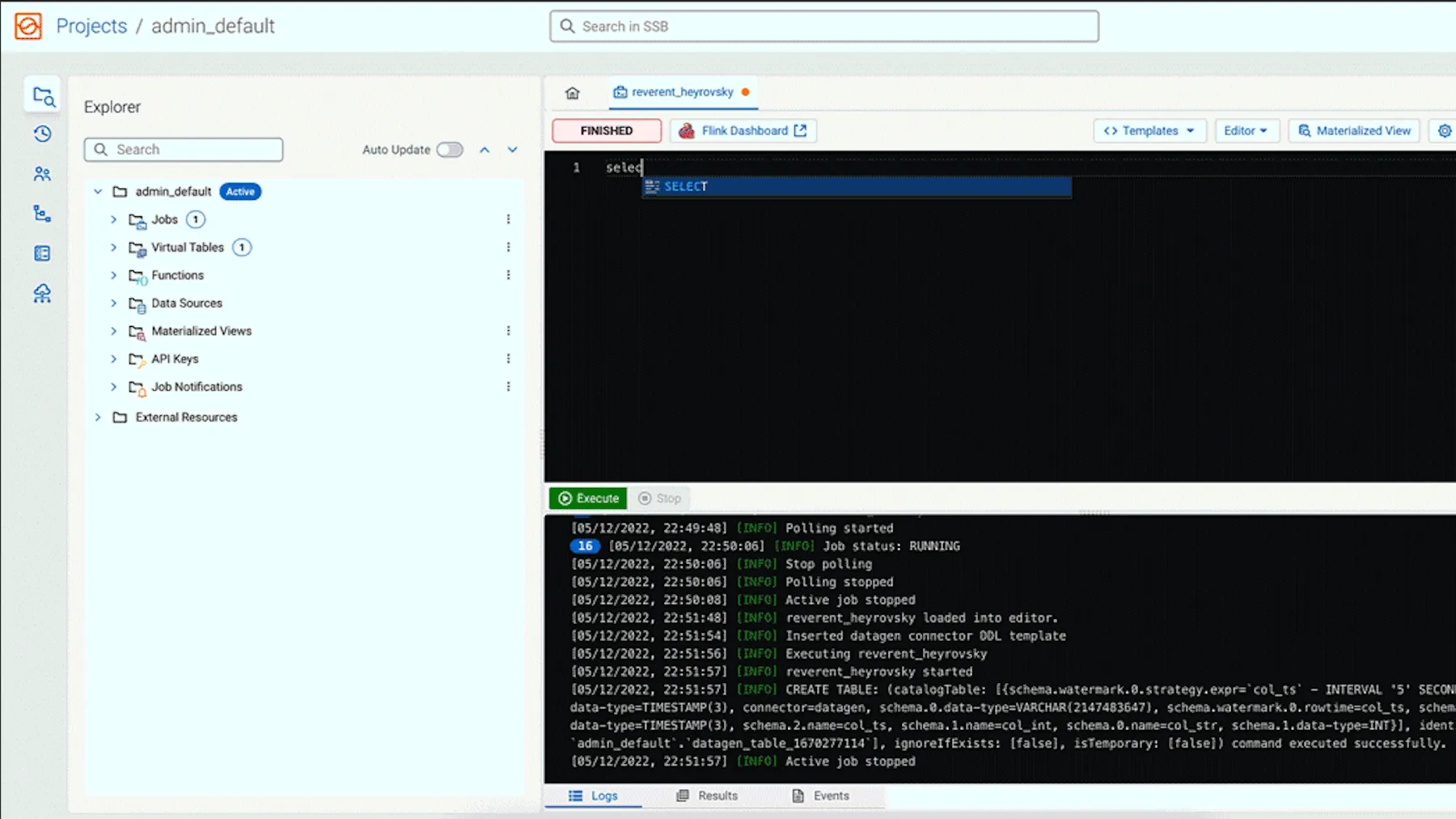
使用 Cloudera SQL Stream Builder 创建即时优惠、动态推荐和主动服务应用。
使分析师能够在实时 Flink 流上使用 SQL,从而为客户提供实时个性化和即时最佳行动决策。

处理复杂的 IoT 流,识别故障的领先指标,并触发自动响应。
我们的 Kafka 和 Flink 操作工具可自动进行部署和扩展,让您的团队能够专注于应用程序逻辑。
一个直观的界面,用于构建、测试和管理 Flink SQL 作业。它加速了开发周期,使更广泛的技术用户能够创建强大的流应用程序。
Cloudera Streaming Analytics 是基于业界领先的流处理引擎 Apache Flink 构建的平台,可满足您团队的关键任务应用程序所需的强大功能和弹性。
一个强大、可扩展且安全的消息传递主干,用于您的实时应用程序。Apache Kafka 和 Cloudera Streams Messaging 为最苛刻的开发工作负载提供可靠的数据传输层。
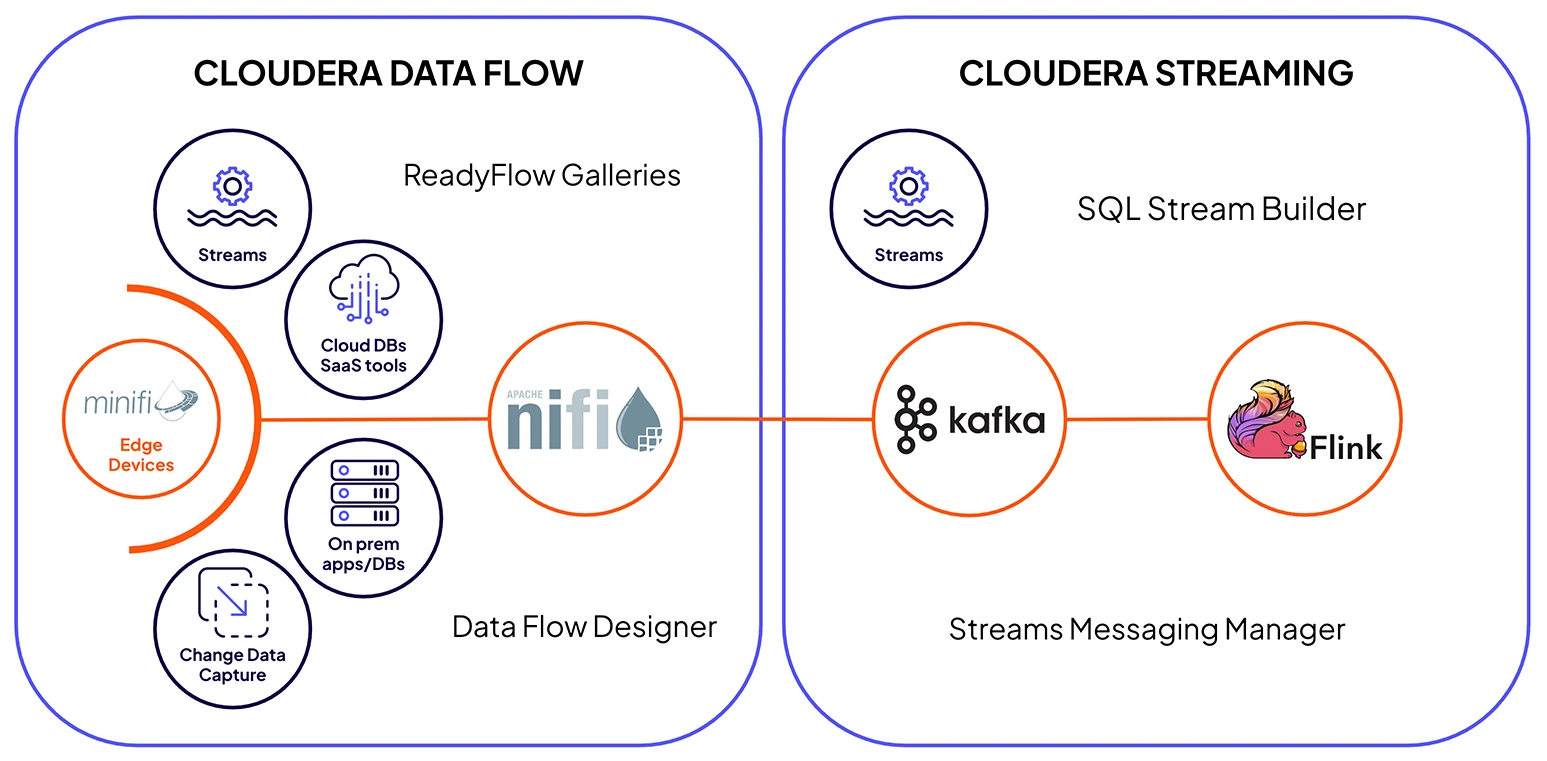
Cloudera Streaming 与 Cloudera Data Flow 相结合,提供集成的企业级组件,使用 NiFi 进行安全摄取,Kafka 实现可靠传输,Flink 实现全数据生命周期的实时处理。
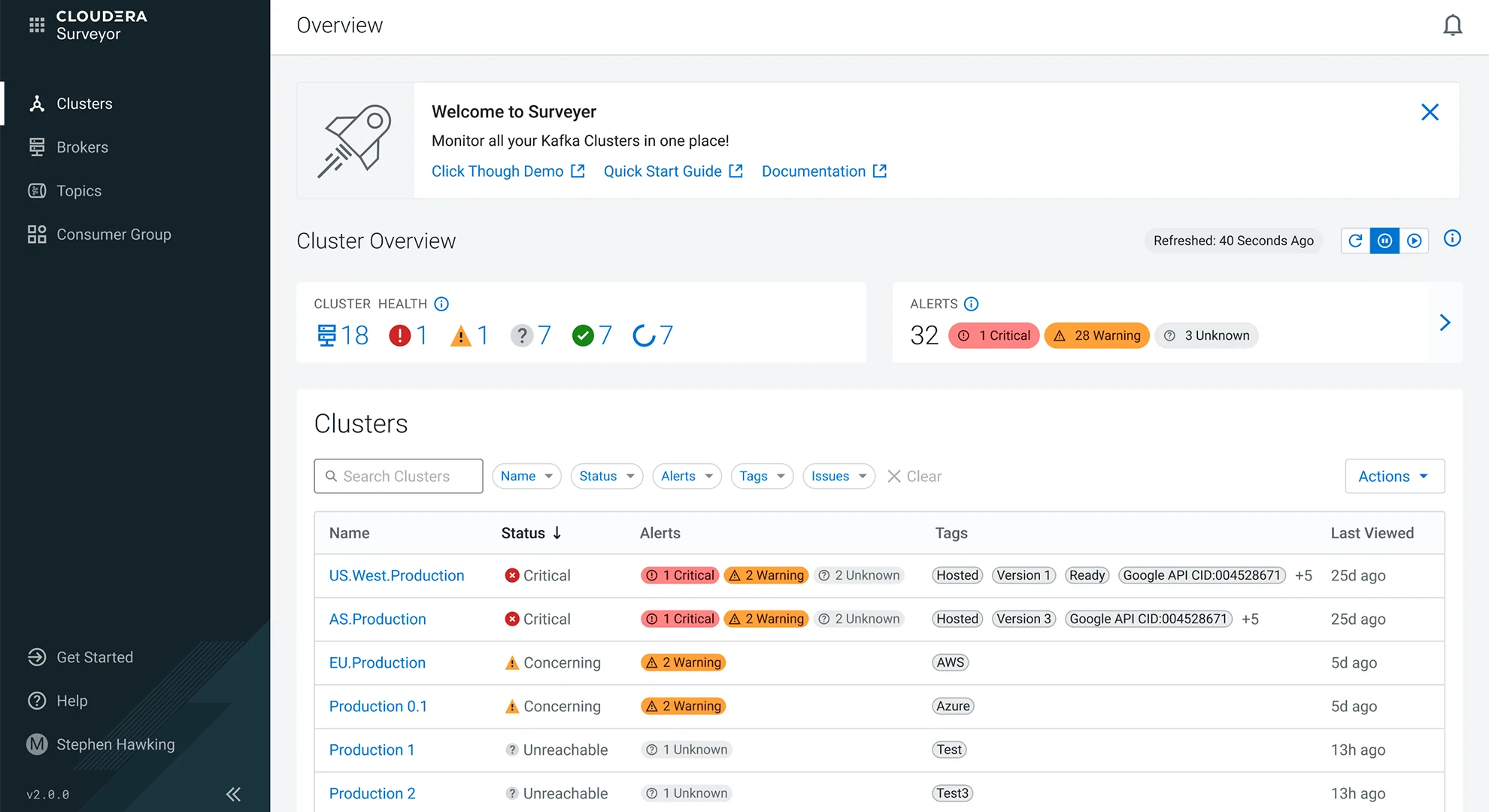
Cloudera Surveyor 为 Kubernetes 上的 Kafka 可观测性提供了一个统一的管理平台,简化了操作并确保应用程序数据主干的健康。模式注册表提供了一个集中的、版本分明的存储库,用于管理数据模式。



部署选项
可在任何地方构建和部署的灵活基础。
对于公有云应用
使您的团队能够在其选择的公有云平台上构建和扩展实时应用程序。
本地部署应用
将其部署为私有云的一部分,以便开发人员能够最大程度地控制延迟和资源。
作为 Kubernetes 的操作员
赋能 DevOps 在符合标准的 Kubernetes 集群中独立提供 Flink 和 Kafka,从而最大化敏捷性和自助服务。