
如果人工智能革命已经让位于一条通用的数据管理真理,那就是在整个数据资产中需要开放性和互操作性。毕竟,人工智能的好坏取决于它实际能够获取的数据。
企业不再愿意投资于彼此脱节的传统技术。孤岛的成本曾经仅仅从基础设施的角度衡量,但如果在价值时间损失和大规模运行人工智能失能方面来衡量,已经呈指数级增长。考虑到这种情况,企业不能不重新思考其数据架构。
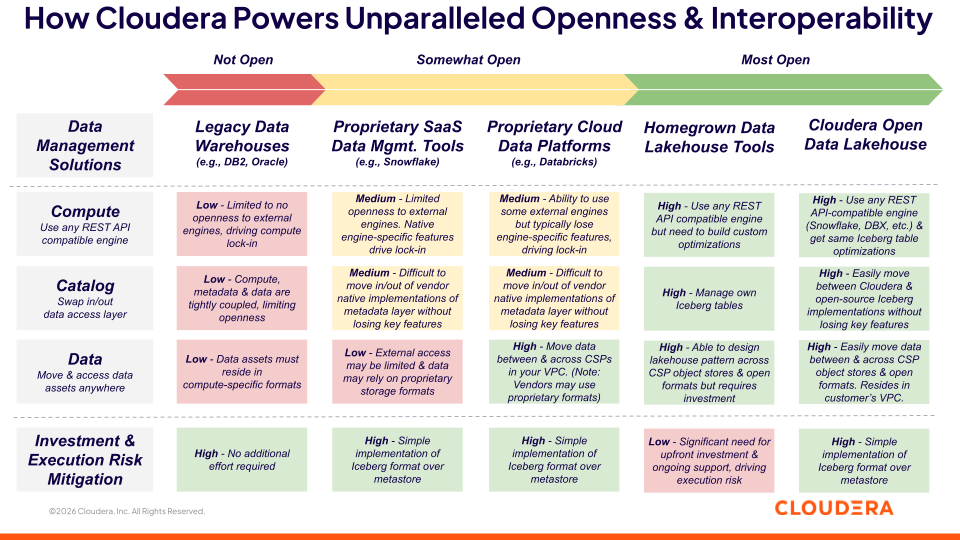
在 Cloudera,我们将开放性定义为三层数据管理架构(见图 1):
开放式计算:无论数据存储在何处,都能使用任何计算引擎
开放目录:能够在不同的数据访问层之间进行交换和互操作,从而确保无论使用何种查看引擎的架构和监管都保持一致
开放数据:无论数据资产位于何处,都能移动和访问这些数据资产的能力
更广泛地说,开放性是 Cloudera 的核心:
Apache Iceberg 的早期支持者:Cloudera 于 2021 年开始在我们的公共云湖仓中支持 Iceberg。其他供应商迅速效仿——这无言地承认 Iceberg 是开放表格格式战争的赢家。2024 年,Databricks 收购了 Tabular,部分原因是其开放治理和复杂功能。在 2025 年,Snowflake 和 Amazon Web Services (AWS) 都投资于扩展 Iceberg 的支持和功能。
开源基金会与生态系统:自 2008 年成立以来,Cloudera 深度融入开源社区,是首家将开源数据湖技术商业化的公司,并持续为 50 多个开源项目做出贡献和支持。我们的开源基础通过允许客户更容易地选择加入或退出 Cloudera 发行版,提供了选择的自由,相比之下,其他供应商的专有叠加层将客户锁定在其产品上。Cloudera 的客户并不是必须留下来;他们选择留下来。
数据管理栈的互操作性:提供开放的计算、目录和数据,确保数据管理层的各个层面都能实现互操作性,使我们的客户无需从零构建,就能真正赢得 AI 时代的胜利。此外,Cloudera 提供了使用任何计算引擎或将数据存储在任何云服务提供商 (CSP) 的灵活性,并提供了对功能的完全访问,无论数据存储在何处或使用何种计算引擎。相反,一些供应商会根据堆栈的所有层是否在同一平台上运行来限制对功能的访问。拥有您的数据。掌控您的数据。使用您的数据——这就是 Cloudera 的承诺。
想深入了解人工智能时代开放性的重要性,请阅读我们的博客:《今天交付的未来:人工智能驱动的数据湖仓》。
