
Cloudera 的开放式基础使企业能够访问 100% 的数据,无论数据位于何处
跨行业,数据团队正在重新思考如何构建和运行不仅仅是存储信息的系统:他们希望将数据转化为情报。同样重要的是,它们需要这些系统能够相互协作。AI 模型、功能管道、商业情报(BI)报告和批处理作业通常跨越多个团队和引擎。在不进行复制或重构的情况下跨越这些边界共享数据现在是一个首要要求。
传统上,组织依赖两层架构:为 BI 和报告优化的数据仓库,以及为大规模人工智能和机器学习(ML)设计的数据湖。这种分离需要高昂代价:复杂的数据移动、专门的工程和跨系统的重复存储很少保持同步。
Cloudera 的开放式数据湖仓架构解决了这一挑战,将分析(BI、临时查询)和人工智能(预测性和生成性人工智能,或 GenAI)工作负载整合在一个单一的、受管的数据基础上。借助 Apache Iceberg 等开放式表格格式,这种统一的数据架构使企业能够将计算带入数据(而不是相反),并为运行更贴近数据的人工智能工作负载奠定了基础。AI 工作负载在数据湖仓上可以直接操作受管理的、版本化的高质量数据。
Cloudera 是唯一一家能将人工智能应用于任何地方数据的数据和人工智能平台公司。利用我们成熟的开源基础,我们提供一致的云体验,融合了公有云、数据中心和边缘。
运行 AI 工作负载的开放基础的重要性
在过去的十年中,企业已经认识到,仅仅具备性能和可扩展性是不够的,灵活性和互操作性决定了长期的成功。尤其是人工智能工作负载,依赖于能够使用不同数据源、框架和工具,不受专有格式或系统的限制。
正是在这方面,开放式表格格式(如 Apache Iceberg)重塑了数据平台的架构。Iceberg 将表的逻辑定义与其物理存储布局分离,允许多个引擎和框架以完整的事务保证读写相同数据。这种开放性使得基础设施的演进和采用新的计算引擎成为可能,而无需重写管道。
运行生产级管道需要一个统一平台,能够连接 AI 生命周期每个阶段的数据、模型和治理。数据和特征工程管道在其中发挥核心作用,其能够持续将原始结构化、半结构化和非结构化数据转化为 AI 支持的特征,保持模型训练和评估的谱系和可重复性。
除了传统的 ML,GenAI 还提出了新的操作要求。团队需要基础设施和数据访问权限,以便进行检索增强生成 (RAG)、在私有数据上微调大型语言模型 (LLM),以及构建结合模型、提示和模型上下文协议 (MCP) (API) 的智能体工作流,以解决特定领域的任务。这些工作负载依赖于表格和非结构化数据(文本、文档、图片和嵌入)——所有数据都由单一的数据和元数据平面管理。此外,可扩展的推理层对于安全高效地部署和服务这些模型至关重要。
随着 AI 工作负载变得越来越多模式和智能体化,访问目录和元数据变得同样重要。AI 管道、检索系统和自主智能体都依赖于元数据来发现数据集、重现训练状态和维护谱系。开放目录为这些系统提供了一种通用的方式来查询、注册和跟踪数据集——无论数据集在哪里或以何种方式处理。
Cloudera 的开放基础使组织能够支持分析、预测性和生成式人工智能工作负载的整个光谱。
Cloudera 的统一数据和人工智能平台
Cloudera的 开放数据湖仓通过建立在 Apache Iceberg 和 REST 目录等开放基础之上,将数据工程、分析和人工智能统一在同一治理架构上。该平台的设计原则是,工作负载(无论是分析型还是人工智能型)应在数据所在的位置运行。通过消除数据移动或重复的摩擦,团队可以构建涵盖摄取、转换、分析和建模运营的连续管道,并实现完整的血脉和治理。
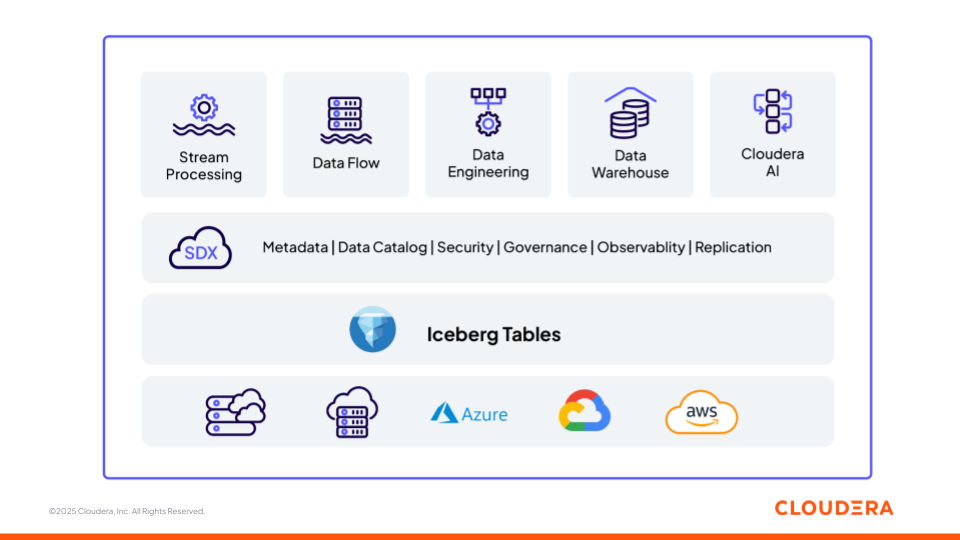
图 1:Cloudera 基于开放基础架构(Apache Iceberg)构建的数据和 AI 平台
接下来,我们来看看 Cloudera 平台中的不同组件(图 1)如何支持团队构建 ML 管道和 GenAI 应用程序,以及数据和 AI 生命周期的不同阶段——从摄取到推理——同时作为一个可互操作的平台运作。每个组件都基于开放标准,确保了跨环境的灵活性和互操作性。
存储:Apache Iceberg
Apache Iceberg 是 Cloudera 湖仓架构的开放、版本化和事务表格式。Iceberg 支持模式演化、时间旅行和原子操作,使分析和人工智能工作负载能够一致地运行于相同的受控数据。Cloudera 提供受控且版本化的基础,确保每个模型、提示或检索任务都基于一致且可追溯的数据视图。
Iceberg 的原生功能,如模式演化,也与 AI 数据集的演变方式高度契合。特征库、训练数据集和检索语料库都可以在 Cloudera 的湖仓中共享相同的 Iceberg 表,通过快照冻结一致视图进行训练,同时新数据持续流入进行推断。这消除了分析表与 AI 专用存储之间的界限。
摄取:Cloudera 动态数据
Cloudera DataFlow 建立在 Apache NiFi 之上,为数据持续迁移到湖仓奠定了基础。它支持从多种企业来源——数据库、API、IoT 设备和事件日志——低延迟地摄取,支持批处理和流式工作负载。NiFi 原生 Apache Iceberg 集成的最新创新现在允许将数据直接写入开放的湖仓,而无需进行中间阶段。NiFi 和 Iceberg 之间的这种紧密耦合降低了管道的复杂性,并使数据摄取更接近于开放表格格式本身。
在实时应用场景中,NiFi、Apache Kafka 和 Apache Flink 构成了事件驱动的摄取结构:NiFi 负责编排和路由数据,Kafka 提供持久的流媒体传输,Flink 则支持实时丰富,然后再将数据持久化到 Iceberg。这种设计可确保数据在所有下游消费者中保持新鲜并受到管理。这种持续不断的多模态数据流也为湖仓的 AI 工作负载提供了动力。通过在 Iceberg 表中持续提供实时数据,并采用一致的治理方式,企业可以向 GenAI 系统提供及时、特定领域的信息,从而使 RAG 管道和智能体工作流更加精确、可靠和有依据。
目录:Cloudera Iceberg REST Catalog
Cloudera Iceberg REST Catalog(基于开放的REST 规范)提供了一个集中式和可互操作的元数据服务,允许任何支持开放规范的第三方引擎(如 Snowflake、Redshift 和 Databricks)对 Iceberg 表进行零复制访问。这是组织的一个关键方面,因为它们不局限于一个平台提供的单一计算引擎,可以灵活地为任务选择最佳计算。用户可以使用他们喜欢的工具,而 Cloudera 提供的相同安全性和治理策略会跟踪数据到任何地方,从而确保跨环境的一致性。
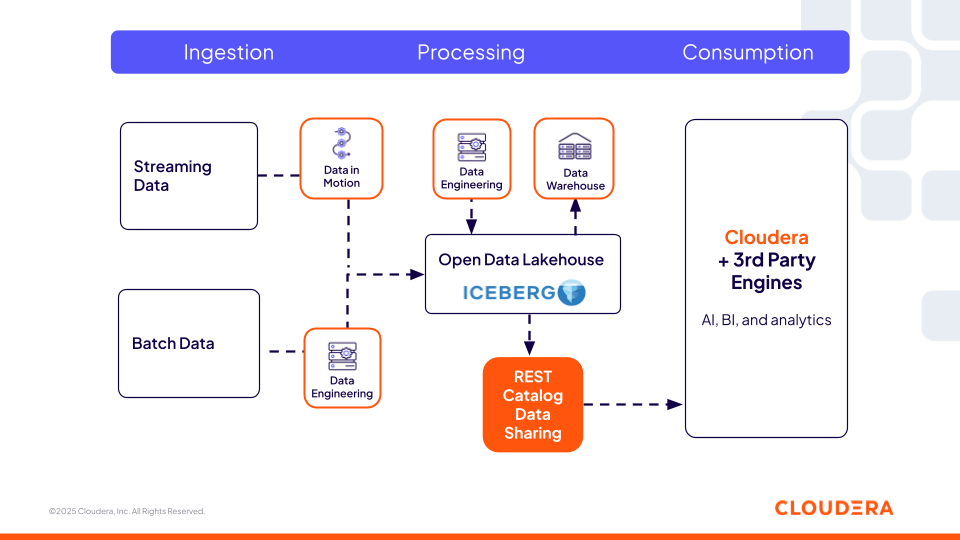
图 2:Cloudera 的 Iceberg REST Catalog 实现了与第三方引擎的互操作性
该目录层对于特征工程流程、智能体式工作流和检索系统动态定位和访问受控数据集至关重要。AI 智能体可以使用 REST Catalog 查询 Iceberg 表,就像查询企业数据的知识图谱一样。他们可以发现可用表,解释其模式,并根据表元数据(如分区、快照和谱系)进行推理,决定使用哪些数据集。
安全和治理:Cloudera SDX
Cloudera Shared Data Experience(SDX) 是一个统一的安全与治理框架,涵盖从摄取到推理的所有服务。SDX 为数据链路、审计、访问控制和策略执行提供单一且一致的层,确保每个工作负载无论运行在哪里,都继承相同的安全模型。它与企业身份系统(LDAP、SSO、OAuth)集成,并支持对结构化和非结构化数据进行细粒度的、基于角色和属性的访问控制。
通过将 SDX 与开放湖屋基础结合,Cloudera 确保数据、模型和 AI 智能体在同一受监管的边界内运行——为分析和生成式 AI 工作负载提供透明度、可重复性和信任。
Cloudera 数据和人工智能服务
统一服务层整合了团队实现转型、分析和运化人工智能所需的所有功能能力,同时处理相同的受控数据。
Data Engineering
Cloudera 数据工程基于开源的 Apache Spark 和 Apache Airflow,提供无服务器服务,直接在 Iceberg 表上构建、编排和扩展数据管道——实现了可靠、可重复的 ETL 和功能管道,适用于混合环境下的分析和 AI 工作负载。
AI 服务
Cloudera AI 服务层实现了 AI 的整个生命周期,从模型训练和微调到安全部署,所有服务均在与 Iceberg 相同的受管数据基础上原生运行。它将模型开发、注册表和推理整合为一个单一的工作流,连接数据工程与人工智能操作。
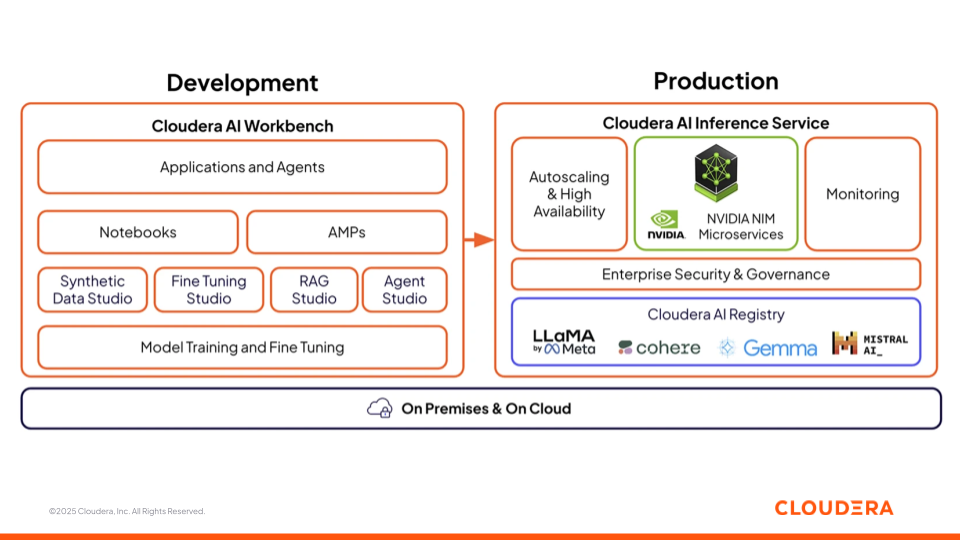
图 3:Cloudera AI 提供的 AI 工作台和推理服务
Cloudera AI Workbench
Cloudera AI Workbench 是一个协作环境,供数据科学家、分析师和工程师开发、微调和测试模型。它汇集了笔记本、低代码应用程序构建器(AMP)和专门的工作室,适用于人工智能开发的各个阶段。为了加速 AI 开发和部署,Cloudera AI Workbench 支持 四个 AI 工作室 ,弥合业务与技术团队之间的鸿沟,促进 AI 项目的协作。
- 当真实数据有限或受限时,合成数据工作室会生成合成数据集,用于测试和模型训练。
- Fine-Tuning Studio 利用企业特定的数据集调整开放的基础模型,以提高相关性和准确性。
- RAG Studio 构建 RAG 管道,将大型语言模型(如 OpenAI、Anthropic、Amazon Bedrock)与相关的私有数据连接起来,以实现有根基的上下文输出。
- Agent Studio 支持创建多步骤的智能体工作流,利用模型、MCP、API 和内部数据源自动化领域特定任务。
所有这些功能都在开放式湖仓(基于 Iceberg 的基础)上运行,使团队能够以受管理、零复制的方式访问特定任务所需的数据。
Cloudera MCP 服务器
Cloudera 还通过一系列新兴的 MCP 服务扩大其人工智能平台的开放性,首先是开源的 Cloudera AI Workbench MCP Server。这项服务旨在实现 AI 系统集成,在 AI 工作台中启用智能体和工具调用功能。它为 LLM 提供了与 Cloudera AI Workbench 功能和组件安全交互的框架——将模型、数据和应用程序引入自动化的企业工作流程中。在这种架构中,智能的智能体能够在可信且受监管的 Cloudera 环境中推理、行动和自动化任务,同时保持受监管行业所需的安全性、控制和可审计性。
Cloudera AI Inference Service
Cloudera AI Inference Service 通过自动扩展、高可用性和端到端可观测性将模型带入生产环境。它支持传统的机器学习模型和大型语言模型(LLM),以低延迟提供预测和响应。可将模型部署为具有企业级安全性的 REST 或 gRPC 端点,确保应用程序和智能体访问的可靠性和一致性。
Cloudera AI Registry 集成在推理层中,提供了一个集中的模型生命周期管理,具有 MLflow 兼容的 API,用于跟踪、版本控制、工件存储和谱系。您可以从多种开放和企业语言模型中选择,如 LlaMa、Cohere、Gemma、Mistral。
推理层还包括内置的监控和可观察性,使团队能够跟踪延迟、吞吐量和模型偏差,同时通过 SDX 治理保持完整的沿袭和合规性。这确保模型预测是可解释且可追溯的,这是企业级人工智能的关键需求。
未来由人工智能驱动,而人工智能则由所有数据驱动
人工智能的成功不仅取决于模型/智能体的能力,也同样取决于数据架构。数据湖仓提供了这一基础,在一个单一的受控数据平面上统一分析、操作和人工智能工作负载。当基于开放标准构建时,它确保数据、元数据和模型可以在工具、云和团队之间无障碍地互操作。
Cloudera AI Workbench、AI Inference Service 和集成的 AI Registry 共同完成了基于开放湖仓基础的数据到 AI 的生命周期。该栈直接构建在受控的 Iceberg 表和开放元数据访问之上,确保每个模型、提示和智能体都运行在可信的版本管理数据上。
企业人工智能的未来将不再由专有堆栈定义,而是由开放的基础决定,这些基础通过共享标准和透明互操作性统一数据、治理和智能。
要了解更多关于如何使用 Cloudera 安全地大规模准备、集成和分析数据的信息,请查看我们的产品演示或注册免费 5 天试用版。
